409 lines
12 KiB
Markdown
409 lines
12 KiB
Markdown
# 📋 Workflow-Beschreibung: LinkedIn Lead Research & Enrichment
|
||
|
||
## 🎯 Zweck
|
||
Automatisierte LinkedIn-Recherche mit KI-gestützter Datenanreicherung für Lead-Generierung. Der Workflow sucht LinkedIn-Profile nach definierten Kriterien, extrahiert Basis-Informationen und reichert diese intelligent mit Kontaktdaten und Unternehmensinformationen an.
|
||
|
||
---
|
||
|
||
|
||
|
||
## 📦 Repository-Struktur
|
||
|
||
```
|
||
n8n-lead-generator/
|
||
├── README.md # Diese Dokumentation
|
||
├── google-search.json # Sub-Workflow für Google-Suche
|
||
├── scraper.csv # Beispiel-Eingabedaten (DataTable)
|
||
├── Leads-N8N-Example.xlsx # Beispiel Zwischen-Output
|
||
└── Leads-N8N-Ergebnisse-Example.xlsx # Beispiel End-Output (angereichert)
|
||
```
|
||
|
||
### **Datei-Beschreibungen:**
|
||
|
||
#### **scraper.csv**
|
||
Beispiel-Struktur für die n8n DataTable "scraper" - die Eingabedaten für den Workflow:
|
||
|
||
**Enthält:**
|
||
- `title` - Berufsbezeichnung/Position (z.B. "Steuerberater")
|
||
- `city` - Stadt für die Suche (z.B. "München")
|
||
- `ready` - Boolean Flag (true/false) für verarbeitungsbereite Einträge
|
||
- `finished` - Boolean Flag markiert bereits bearbeitete Jobs
|
||
- `pages` - Anzahl zu durchsuchender Google-Seiten
|
||
- `startIndex` - Start-Position für Pagination
|
||
|
||
**Verwendung:**
|
||
Import diese CSV in eine n8n DataTable namens "scraper" um den Workflow zu initialisieren.
|
||
|
||
#### **Leads-N8N-Example.xlsx**
|
||
Beispiel-Output nach Phase 1 (Google Search & Basic Extraction):
|
||
|
||
**Enthält:**
|
||
- ID (LinkedIn-URL)
|
||
- Titel (vollständiger LinkedIn-Titel)
|
||
- Beschreibung (LinkedIn-Bio/Beschreibung)
|
||
- Link (LinkedIn-Profil-URL)
|
||
- Vorname
|
||
- Nachname
|
||
- Branche *(initial leer - Trigger für AI)*
|
||
|
||
**Verwendung:**
|
||
Zeigt die Struktur des Google Sheets "Leads-N8N-2" - erstelle ein entsprechendes Sheet mit diesen Spalten.
|
||
|
||
#### **Leads-N8N-Ergebnisse-Example.xlsx**
|
||
Beispiel-Output nach Phase 2 (AI-Enrichment):
|
||
|
||
**Enthält alle angereicherten Daten:**
|
||
- ID
|
||
- Vorname, Nachname
|
||
- Branche/Industry
|
||
- Straße, PLZ, Ort, Land
|
||
- E-Mail
|
||
- Telefon
|
||
- Website
|
||
|
||
**Verwendung:**
|
||
Zeigt die Struktur des Google Sheets "Leads-N8N-Ergebnisse" - erstelle ein entsprechendes Sheet mit diesen Spalten.
|
||
|
||
#### **google-search.json**
|
||
Sub-Workflow der von "Get Search Results" aufgerufen wird:
|
||
|
||
**Funktionalität:**
|
||
- Führt Google-Suche mit Custom Search API durch
|
||
- Parameter: search query, pages, start index
|
||
- Gibt strukturierte Suchergebnisse zurück
|
||
- Filtert auf LinkedIn-Profile
|
||
|
||
**Installation:**
|
||
Importiere diesen Workflow separat in n8n und verlinke ihn im Haupt-Workflow.
|
||
|
||
---
|
||
|
||
## 🚀 Setup & Installation
|
||
|
||
### **Schritt 1: DataTable erstellen**
|
||
```bash
|
||
1. In n8n: Gehe zu "Data"
|
||
2. Erstelle neue DataTable "scraper"
|
||
3. Importiere scraper.csv
|
||
```
|
||
|
||
### **Schritt 2: Google Sheets vorbereiten**
|
||
```bash
|
||
1. Erstelle Google Sheet "Leads-N8N-2"
|
||
- Importiere Spalten aus Leads-N8N-Example.xlsx
|
||
|
||
2. Erstelle Google Sheet "Leads-N8N-Ergebnisse"
|
||
- Importiere Spalten aus Leads-N8N-Ergebnisse-Example.xlsx
|
||
|
||
3. Verbinde Google Sheets mit n8n (OAuth2)
|
||
```
|
||
|
||
### **Schritt 3: Workflows importieren**
|
||
```bash
|
||
1. Importiere google-search.json als Sub-Workflow
|
||
2. Importiere Haupt-Workflow (aus deinem n8n)
|
||
3. Verlinke "Get Search Results" Node mit Sub-Workflow
|
||
```
|
||
|
||
### **Schritt 4: API-Credentials konfigurieren**
|
||
```bash
|
||
1. Google Custom Search API Key
|
||
2. OpenAI API Key (GPT-4 oder GPT-4o)
|
||
3. Google Sheets OAuth2 Credentials
|
||
```
|
||
|
||
### **Schritt 5: Test-Run**
|
||
```bash
|
||
1. Füge 5 Test-Einträge in scraper.csv ein
|
||
2. Setze ready=true, finished=false
|
||
3. Trigger Workflow manuell
|
||
4. Prüfe Outputs in beiden Google Sheets
|
||
```
|
||
|
||
---
|
||
|
||
## 🔄 Workflow-Ablauf
|
||
|
||
### **Phase 1: Initialisierung & Suche**
|
||
|
||
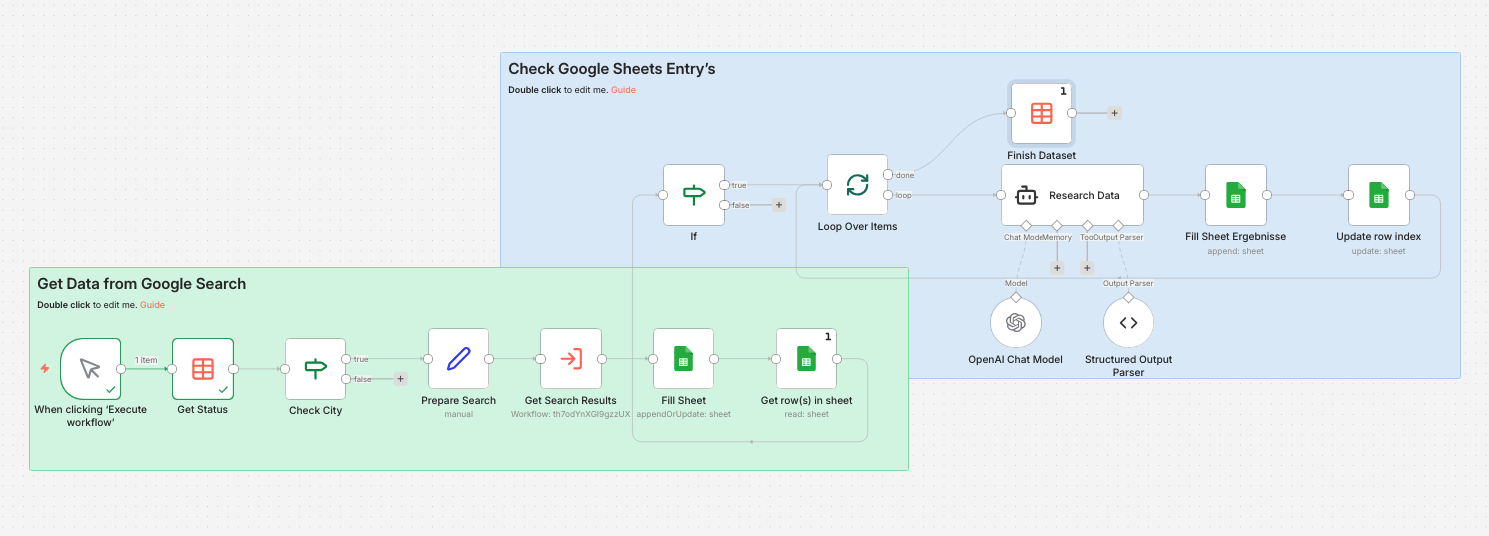
1. **Manual Trigger**
|
||
- Startet den Workflow manuell
|
||
|
||
2. **Get Status** (DataTable)
|
||
- Liest aus `scraper.csv` / DataTable "scraper"
|
||
- Filtert auf `ready = true` (bereite Jobs)
|
||
- Liefert typisch ~80 Suchanfragen mit Kriterien (Titel, Stadt, etc.)
|
||
|
||
3. **Check City**
|
||
- Validiert ob erforderliche Felder vorhanden sind
|
||
- Prüft: `city` nicht leer ODER `finished = false`
|
||
- Filtert ungültige/bereits bearbeitete Einträge aus
|
||
|
||
4. **Prepare Search**
|
||
- Bereitet die Suchparameter vor
|
||
- Kombiniert: `title` + `city` zu Suchstring
|
||
- Format: z.B. "Steuerberater München"
|
||
|
||
5. **Get Search Results** (Sub-Workflow)
|
||
- Ruft `google-search.json` Workflow auf
|
||
- Suche mit: `"[title] [city] site:linkedin.com/in"`
|
||
- Parameter: Seiten-Anzahl, Start-Index
|
||
- Liefert LinkedIn-URLs und Metadaten zurück
|
||
|
||
6. **Fill Sheet** (Google Sheets)
|
||
- Schreibt Basis-Daten in "Leads-N8N-2" Tabelle (siehe `Leads-N8N-Example.xlsx`)
|
||
- Felder: ID, Titel, Beschreibung, Link, Vorname, Nachname
|
||
- Verwendet `appendOrUpdate` mit ID als Matching-Key
|
||
- Duplikate werden automatisch aktualisiert
|
||
|
||
---
|
||
|
||
### **Phase 2: Datenanreicherung (AI-Loop)**
|
||
|
||
7. **Get row(s) in sheet** (Google Sheets)
|
||
- Holt frisch geschriebene Daten aus "Leads-N8N-2" zurück
|
||
- Prüft Status der einzelnen Einträge
|
||
- Identifiziert Einträge die noch angereichert werden müssen
|
||
|
||
8. **IF** (Conditional Check)
|
||
- Prüft ob das Feld "Branche" leer ist
|
||
- Nur leere Einträge werden weiterverarbeitet
|
||
- Verhindert doppelte AI-Verarbeitung (Kosten-Optimierung)
|
||
|
||
9. **Loop Over Items** (Split in Batches)
|
||
- **Batch Size: 5** Items pro Durchlauf
|
||
- Begrenzt Token-Verbrauch bei ChatGPT
|
||
- Verhindert Rate-Limiting und Timeouts
|
||
- Loop läuft bis alle Items verarbeitet sind
|
||
|
||
10. **Research Data** (AI Agent)
|
||
- **OpenAI Chat Model** (GPT-4 oder GPT-4o)
|
||
- **Structured Output Parser** für konsistente Datenstruktur
|
||
- Extrahiert aus LinkedIn-Profil + Websuche:
|
||
- ✉️ E-Mail-Adresse
|
||
- 📞 Telefonnummer
|
||
- 🌐 Website
|
||
- 🏢 Branche/Industry
|
||
- 📍 Vollständige Adresse (Straße, PLZ, Ort, Land)
|
||
- **Settings:**
|
||
- Temperature: **0.0** (maximale Konsistenz)
|
||
- top_p: **0.1** (deterministisch)
|
||
- Execute Once: **OFF** (verarbeitet jedes Item einzeln)
|
||
|
||
11. **Fill Sheet Ergebnisse** (Google Sheets)
|
||
- Schreibt angereicherte Daten in "Leads-N8N-Ergebnisse" (siehe `Leads-N8N-Ergebnisse-Example.xlsx`)
|
||
- Verwendet ID als Matching-Key für Updates
|
||
- Felder: Vorname, Nachname, Straße, PLZ, Ort, Land, Mail, Telefon, Website, Branche
|
||
|
||
12. **Update row index** (Google Sheets)
|
||
- Markiert verarbeitete Einträge in "Leads-N8N-2"
|
||
- Verhindert Re-Processing im nächsten Loop
|
||
- Aktualisiert Status-Felder
|
||
|
||
13. **Loop zurück** zu Step 9
|
||
- Verarbeitet nächsten Batch (5 Items)
|
||
- Wiederholt bis alle Items durch sind
|
||
- Automatische Loop-Beendigung wenn keine Items mehr
|
||
|
||
---
|
||
|
||
### **Phase 3: Abschluss**
|
||
|
||
14. **Finish Dataset** (DataTable)
|
||
- Markiert den ursprünglichen Job in `scraper` als `finished = true`
|
||
- Verhindert Re-Processing bei erneutem Workflow-Start
|
||
- Aktualisiert Statistiken/Timestamps
|
||
|
||
---
|
||
|
||
## 📊 Datenfluss
|
||
|
||
```
|
||
Eingabe (scraper.csv):
|
||
├─ title: "Steuerberater"
|
||
├─ city: "München"
|
||
├─ pages: 3
|
||
├─ startIndex: 1
|
||
├─ ready: true
|
||
└─ finished: false
|
||
|
||
↓ [Google Search via google-search.json]
|
||
|
||
Zwischen-Output (Leads-N8N-Example.xlsx):
|
||
├─ ID: "linkedin.com/in/max-mustermann"
|
||
├─ Titel: "Max Mustermann - Steuerberater München"
|
||
├─ Beschreibung: "Steuerberater | Wirtschaftsprüfer..."
|
||
├─ Link: "https://linkedin.com/in/max-mustermann"
|
||
├─ Vorname: "Max"
|
||
├─ Nachname: "Mustermann"
|
||
└─ Branche: [LEER] ← Trigger für AI
|
||
|
||
↓ [AI Research mit GPT-4o]
|
||
|
||
End-Output (Leads-N8N-Ergebnisse-Example.xlsx):
|
||
├─ ID: "linkedin.com/in/max-mustermann"
|
||
├─ Vorname: "Max"
|
||
├─ Nachname: "Mustermann"
|
||
├─ Straße: "Maximilianstraße 15"
|
||
├─ PLZ: "80539"
|
||
├─ Ort: "München"
|
||
├─ Land: "Deutschland"
|
||
├─ Mail: "max@stb-mustermann.de"
|
||
├─ Telefon: "+49 89 123456"
|
||
├─ Website: "www.stb-mustermann.de"
|
||
└─ Branche: "Steuerberatung"
|
||
```
|
||
|
||
---
|
||
|
||
## 📁 Beispieldaten
|
||
|
||
### **scraper.csv Format:**
|
||
```csv
|
||
title,city,pages,startIndex,ready,finished
|
||
Steuerberater,München,3,1,true,false
|
||
Rechtsanwalt,Berlin,2,1,true,false
|
||
IT-Berater,Hamburg,3,1,true,false
|
||
```
|
||
|
||
### **Leads-N8N-Example.xlsx Spalten:**
|
||
- ID
|
||
- Titel
|
||
- Beschreibung
|
||
- Link
|
||
- Vorname
|
||
- Nachname
|
||
- Branche *(leer)*
|
||
- Straße *(leer)*
|
||
- PLZ *(leer)*
|
||
- Ort *(leer)*
|
||
- Land *(leer)*
|
||
- Mail *(leer)*
|
||
- Telefon *(leer)*
|
||
- Website *(leer)*
|
||
|
||
### **Leads-N8N-Ergebnisse-Example.xlsx Spalten:**
|
||
- ID
|
||
- Vorname
|
||
- Nachname
|
||
- Branche *(gefüllt von AI)*
|
||
- Straße *(gefüllt von AI)*
|
||
- PLZ *(gefüllt von AI)*
|
||
- Ort *(gefüllt von AI)*
|
||
- Land *(gefüllt von AI)*
|
||
- Mail *(gefüllt von AI)*
|
||
- Telefon *(gefüllt von AI)*
|
||
- Website *(gefüllt von AI)*
|
||
|
||
---
|
||
|
||
## ⚙️ Technische Details
|
||
|
||
### **Performance:**
|
||
- **Verarbeitungsgeschwindigkeit:** ~5-10 Items pro Minute
|
||
- **Batch-Größe:** 5 Items (Token-Optimierung)
|
||
- **Durchsatz:** ~80 Leads in 30-45 Minuten
|
||
|
||
### **Token-Verbrauch (geschätzt):**
|
||
- Pro Item: ~700 Tokens (Input + Output)
|
||
- Pro Batch (5 Items): ~3.500 Tokens
|
||
- Gesamt (80 Items): ~56.000 Tokens
|
||
|
||
### **Kosten (GPT-4o):**
|
||
- Input: ~$0.28 (56k Tokens × $5/1M)
|
||
- Output: ~$0.84 (56k Tokens × $15/1M)
|
||
- **Total: ~$1.12 pro Workflow-Durchlauf**
|
||
- **Pro Lead: ~$0.014**
|
||
|
||
### **Error Handling:**
|
||
- Retry on Fail: Aktiviert im Research Data Node
|
||
- Loop-basierte Verarbeitung: Fehler stoppen nicht den gesamten Workflow
|
||
- Duplikat-Prevention: ID-basiertes Matching verhindert doppelte Einträge
|
||
|
||
---
|
||
|
||
## 🎯 Use Cases
|
||
|
||
**Ideal für:**
|
||
- 🔍 Lead-Generierung für B2B-Sales
|
||
- 📊 Marktforschung & Wettbewerbsanalyse
|
||
- 🎯 Account-Based Marketing (ABM)
|
||
- 📈 CRM-Datenanreicherung
|
||
- 🤝 Recruiting & Headhunting
|
||
|
||
**Branchen:**
|
||
- Steuerberatung
|
||
- Unternehmensberatung
|
||
- Rechtsberatung
|
||
- IT-Dienstleistungen
|
||
- Finanzdienstleistungen
|
||
- Medizin & Healthcare
|
||
- Architektur & Ingenieurwesen
|
||
|
||
---
|
||
|
||
## 🔒 Datenschutz & Compliance
|
||
|
||
**Wichtig:**
|
||
- Daten stammen aus **öffentlich zugänglichen LinkedIn-Profilen**
|
||
- Keine Speicherung sensibler persönlicher Daten
|
||
- DSGVO-konform bei korrekter Verwendung (Opt-out respektieren)
|
||
- Nur geschäftliche Kontaktdaten werden verarbeitet
|
||
- Empfehlung: Opt-In für Marketing-Kommunikation einholen
|
||
|
||
---
|
||
|
||
## 🚀 Vorteile
|
||
|
||
✅ **Skalierbar:** Verarbeitet hunderte Leads automatisch
|
||
✅ **Kosteneffizient:** ~$0.014 pro Lead (bei GPT-4o)
|
||
✅ **Konsistent:** Temperature 0.0 = reproduzierbare Ergebnisse
|
||
✅ **Robust:** Loop-basiert, fehlertoleranz durch Batch-Verarbeitung
|
||
✅ **Wartbar:** Modularer Aufbau, einfach erweiterbar
|
||
✅ **Dokumentiert:** Vollständige Beispieldaten und Setup-Guide
|
||
|
||
---
|
||
|
||
## 🛠️ Troubleshooting
|
||
|
||
### **Problem: Keine Ergebnisse in Leads-N8N-Ergebnisse**
|
||
**Lösung:** Prüfe ob "Branche" Feld in Leads-N8N-2 leer ist (Trigger für AI)
|
||
|
||
### **Problem: Token Limit Exceeded**
|
||
**Lösung:** Reduziere Batch Size von 5 auf 3 im Loop Over Items Node
|
||
|
||
### **Problem: Google Search gibt keine Ergebnisse**
|
||
**Lösung:** Prüfe Google Custom Search API Quota & Credentials
|
||
|
||
### **Problem: Workflow stoppt mittendrin**
|
||
**Lösung:** Prüfe Error Logs - meist OpenAI Rate Limiting, Pause von 30 Sek. einbauen
|
||
|
||
---
|
||
|
||
## 📝 Changelog
|
||
|
||
### Version 3.0 (2026-01-12)
|
||
- ✅ Stable Production Release
|
||
- ✅ Loop-basiertes Batch-Processing implementiert
|
||
- ✅ Beispieldaten hinzugefügt (CSV + XLSX)
|
||
- ✅ Sub-Workflow für Google-Suche dokumentiert
|
||
- ✅ Vollständige Setup-Anleitung
|
||
|
||
---
|
||
|
||
## 🤝 Contributing
|
||
|
||
Pull Requests sind willkommen! Bei größeren Änderungen bitte zuerst ein Issue öffnen.
|
||
|
||
---
|
||
|
||
## 📄 Lizenz
|
||
|
||
Joachim Hummel © 2026
|
||
|
||
---
|
||
|
||
**Version:** 3.0 (Stable)
|
||
**Erstellt:** Januar 2026
|
||
**Status:** Production-Ready ✅
|